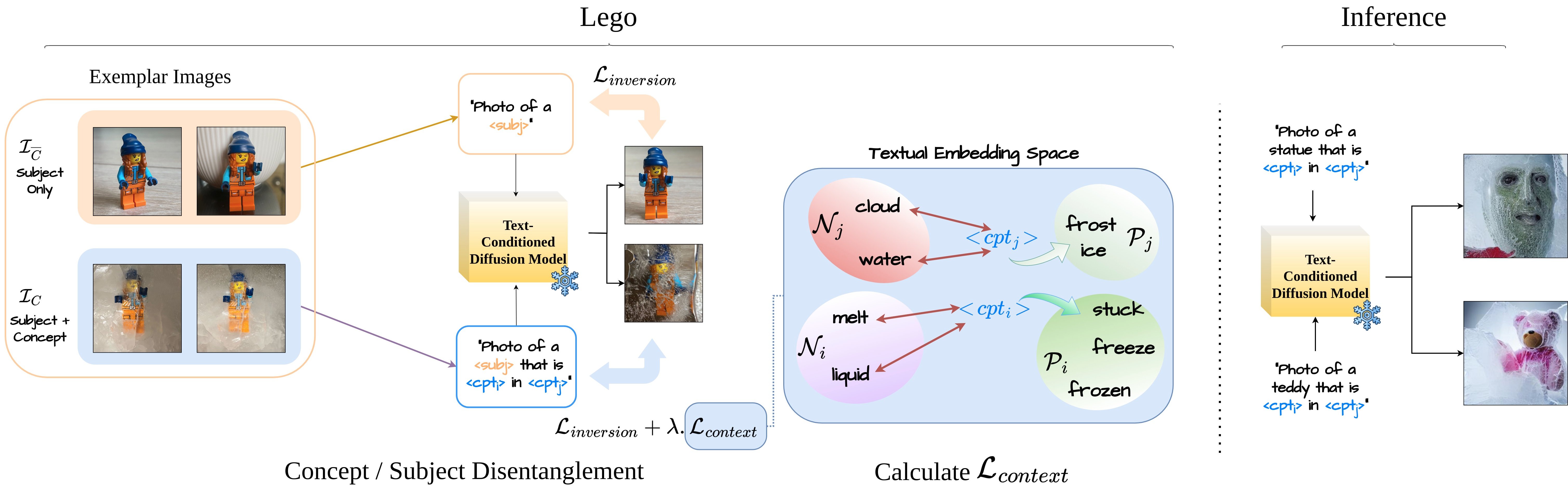
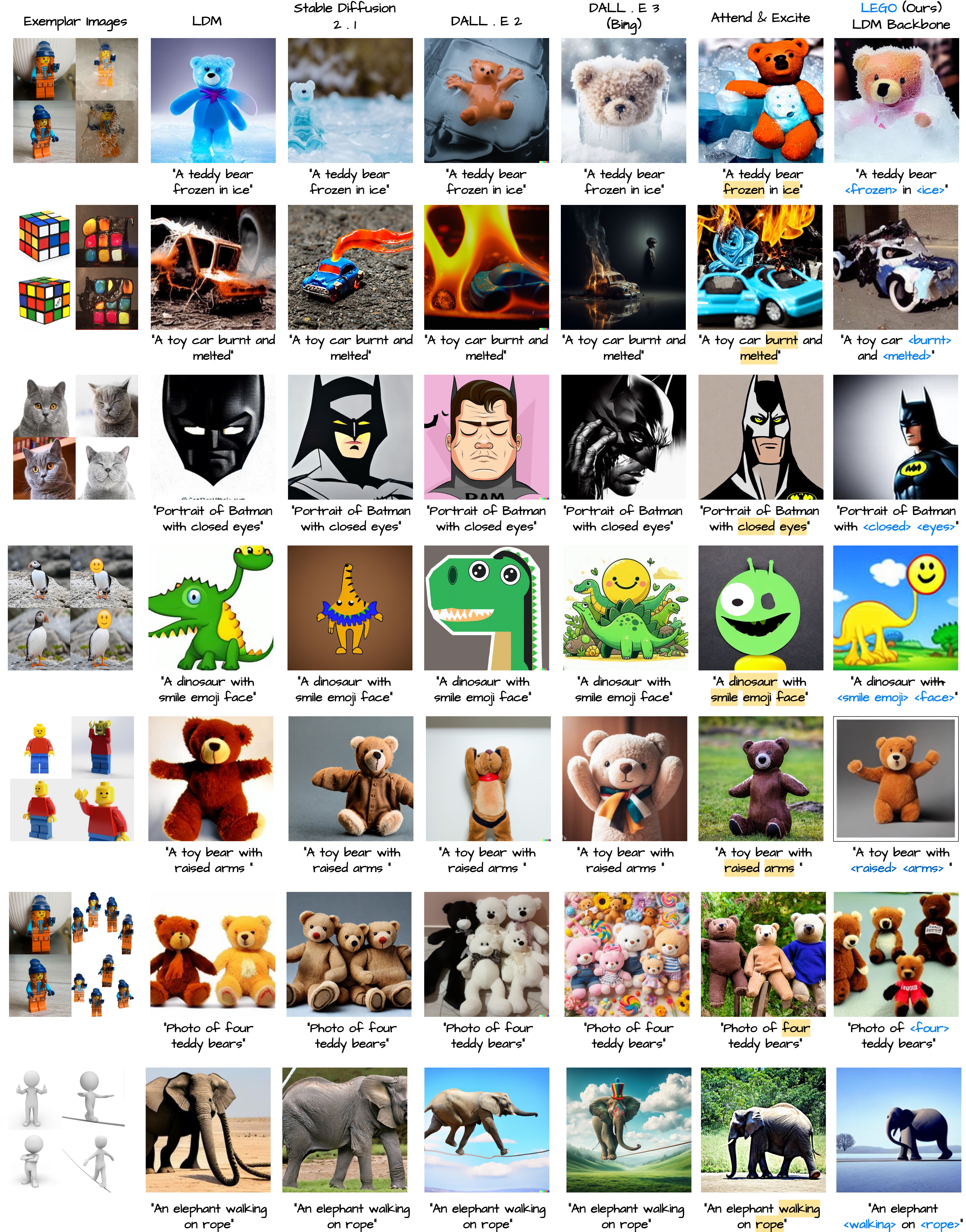
Diffusion models have revolutionized generative content creation and text-to-image (T2I) diffusion models in particular have increased the creative freedom of users by allowing scene synthesis using natural language. T2I models excel at synthesizing concepts such as nouns, appearances, and styles. To enable customized content creation based on a few example images of a concept, methods such as Textual Inversion and DreamBooth invert the desired concept and enable synthesizing it in new scenes. However, inverting more general concepts that go beyond object appearance and style (adjectives and verbs) through natural language, remains a challenge. Two key characteristics of these concepts contribute to the limitations of current inversion methods. 1) Adjectives and verbs are entangled with nouns (subject) and can hinder appearance-based inversion methods, where the subject appearance leaks into the concept embedding and 2) describing such concepts often extends beyond single word embeddings (“being frozen in ice”, “walking on a tightrope”, etc.) that current methods do not handle. In this study, we introduce Lego, a textual inversion method designed to invert subject entangled concepts from a few example images. Lego disentangles concepts from their associated subjects using a simple yet effective Subject Separation step and employs a Context Loss that guides the inversion of single/multi-embedding concepts. In a thorough user study, Lego-generated concepts were preferred over 70% of the time when compared to the baseline. Additionally, visual question answering using a large language model suggested Lego-generated concepts are better aligned with the text description of the concept.